According to Wikipedia, a smoke test is a preliminary test that reveals simple failures severe enough to (for example) reject a prospective software release. The process of smoke testing aims to determine whether the application is so badly broken as to make further immediate testing unnecessary. If we consider our dockerized blog-helm web application, a possible smoke test can be: can we pull the image from the registry? If we run the image, does the container stay alive or does it crash immediately? In this post, I’ll implement this in an extra build configuration in TeamCity with a generic bash script doing the actual work.
First we need to create the new build configuration:
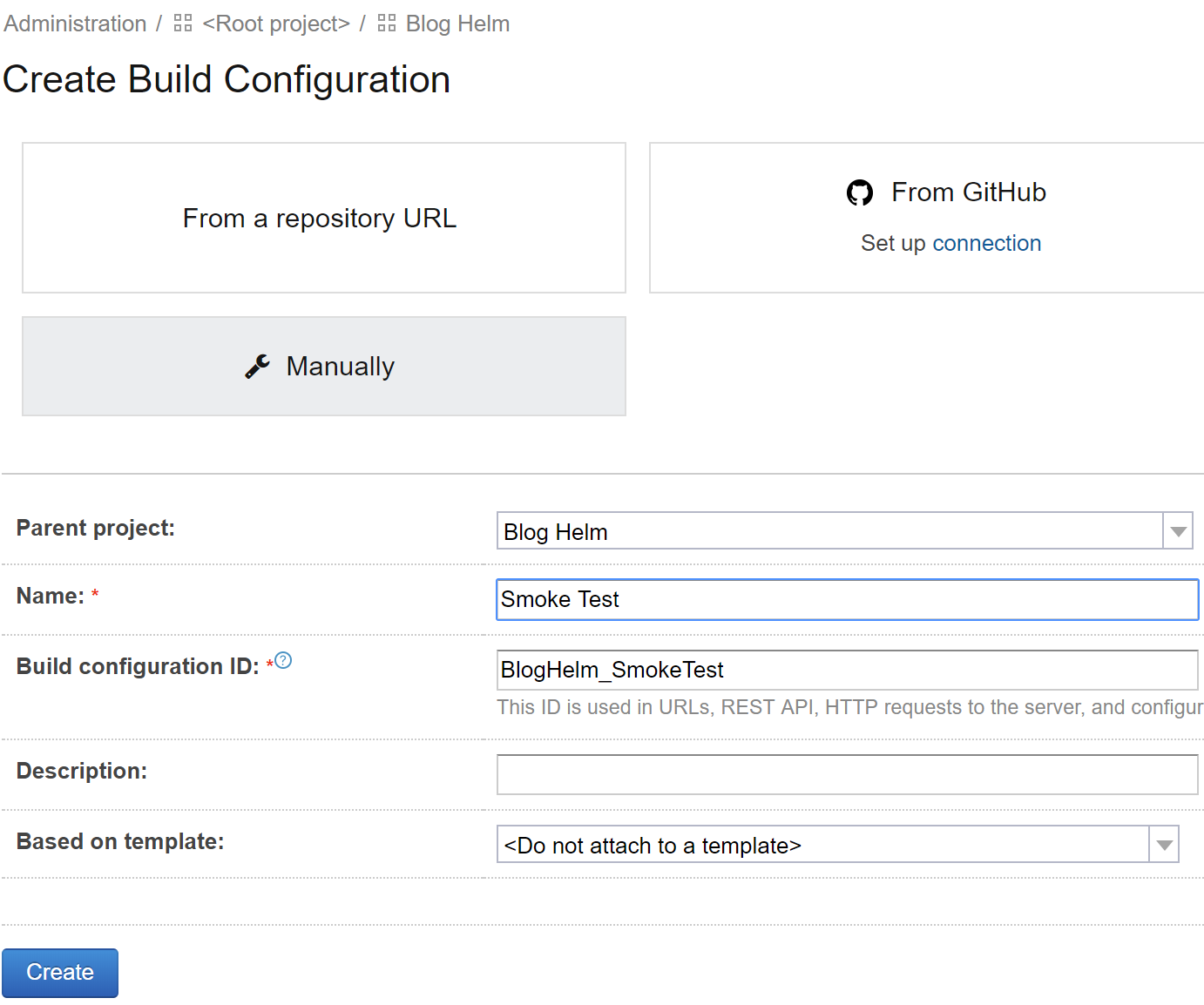
Just like in the previous post, we need to make it part of the build chain, so it needs the VCS root:
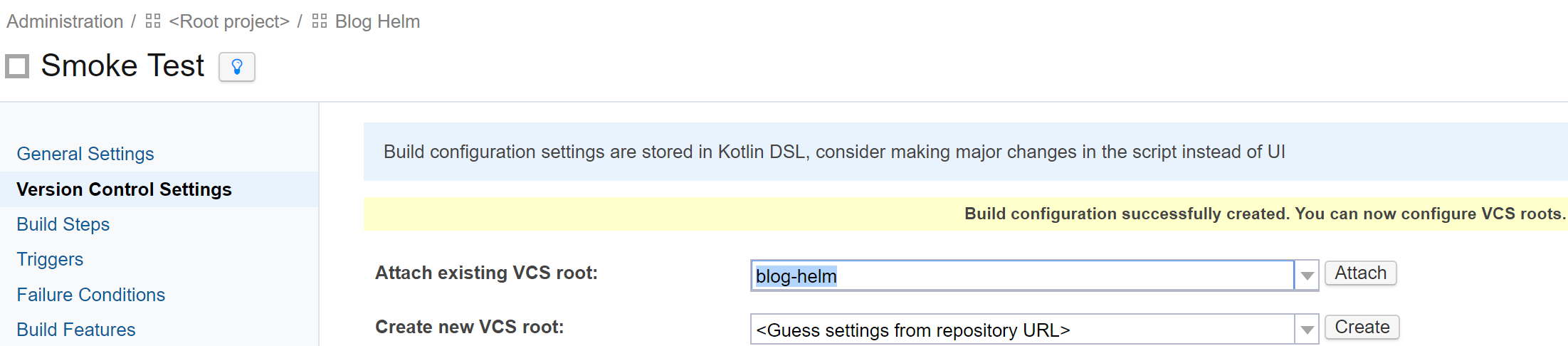
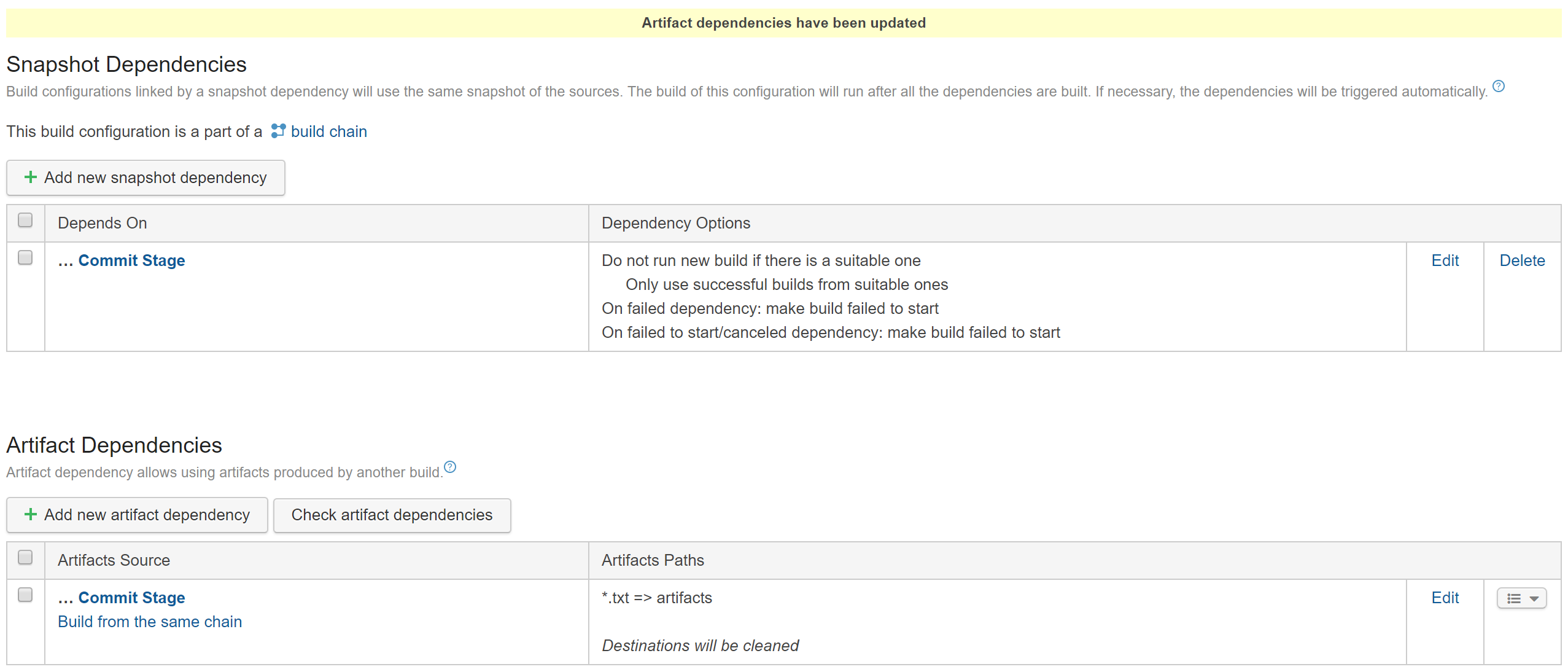
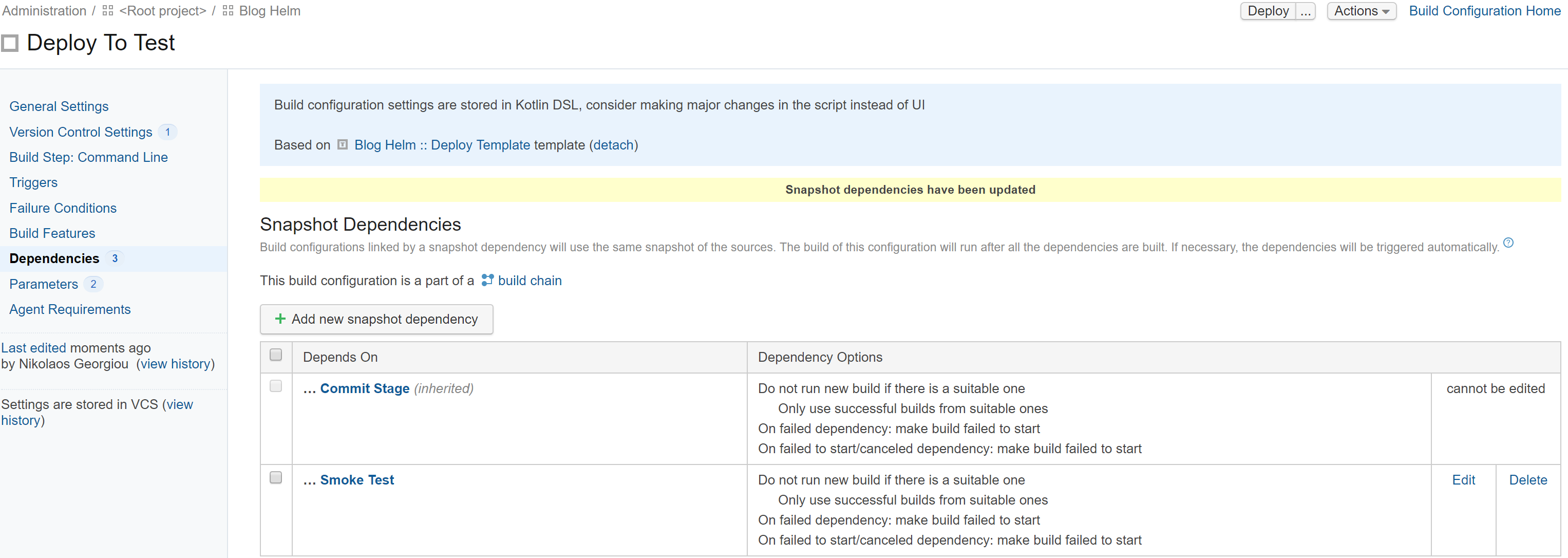
and the snapshot dependency. Note that the only artifact needed is the image-tag.txt file that contains the Docker image tag name.
I’d like to smoke test all feature branches automatically on every commit, so I configure a Finished Build trigger:
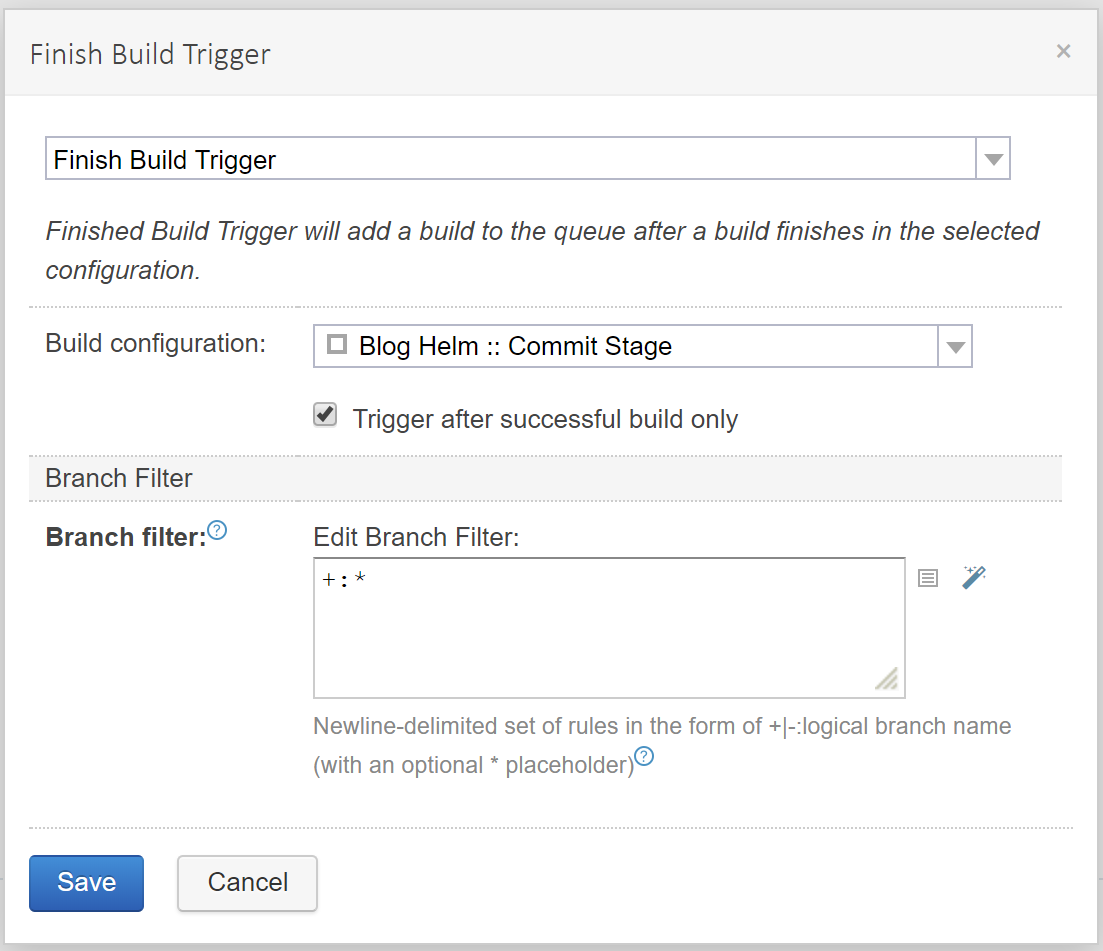
and I don’t want to be able to deploy to the test environment unless the smoke test has passed, so I add another snapshot dependency to the Deploy to Test build configuration:
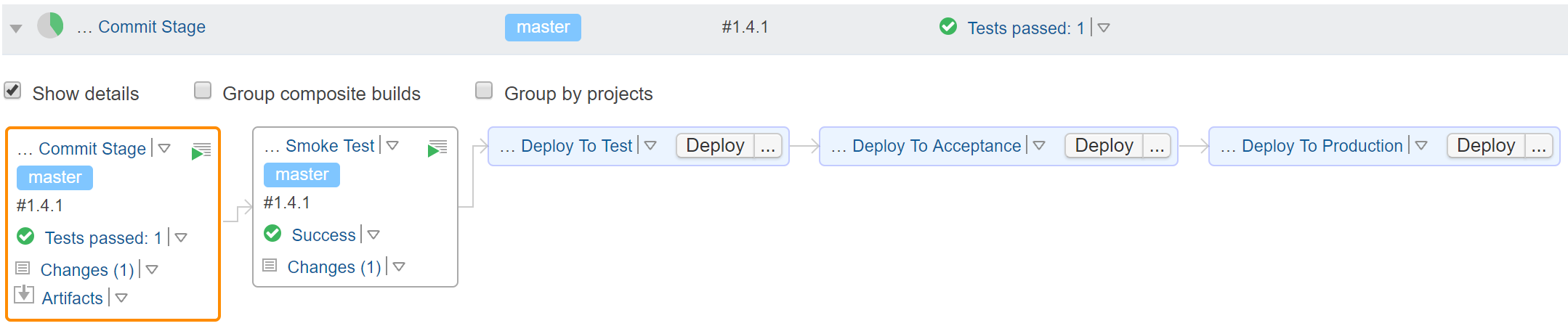
With these changes we have a new build chain with the Smoke Test build configuration in between Commit Stage and Deploy to Test:
Now the build pipeline is configured and we just need to write the script that performs the smoke test. The script is a bit long at 98 lines of Bash, so I’ll just link to it if you want to read it. Its logic is roughly as follows:
- Pull the image from the custom docker registry
- Start a container with this image in the background (so that the script can continue)
- Wait until the container starts (it retries 5 times with 5 seconds sleep between each retry). If the container can't start at all, either it's completely wrong, or the host is too slow, or something else weird is going on.
- Wait to verify that the container stays up (same retry rules as before). This is the actual substance of this smoke test. The container starts, but does it stay up? This is supposed to be a web application, so it should stay up to serve incoming HTTP requests.
- Cleanup: stop the container, print its logs (useful for troubleshooting), remove the container.
Let’s see an example build log of a successful smoke test:
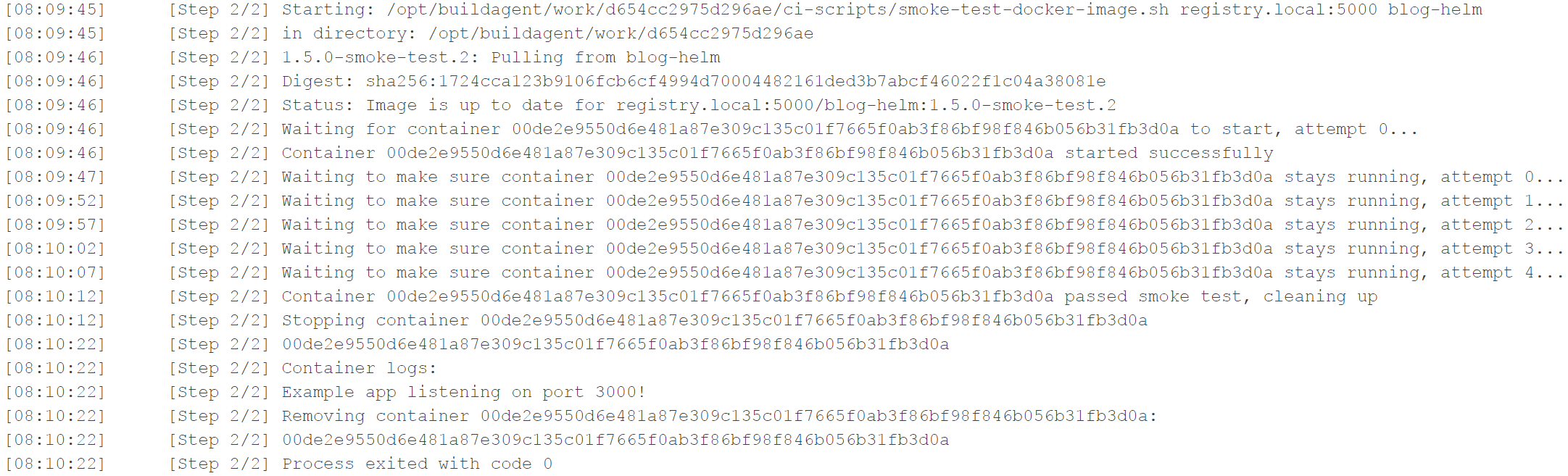
You can see that the container starts and stays up. The script tried 5 times and the container didn’t die inexplicably in between, so that’s good enough as far this smoke test is concerned.
To get a red build out of this smoke test, I modified the CMD instruction in the Dockerfile so that it references a non-existing JavaScript file (indexx.js instead of index.js). This is the resulting build log:
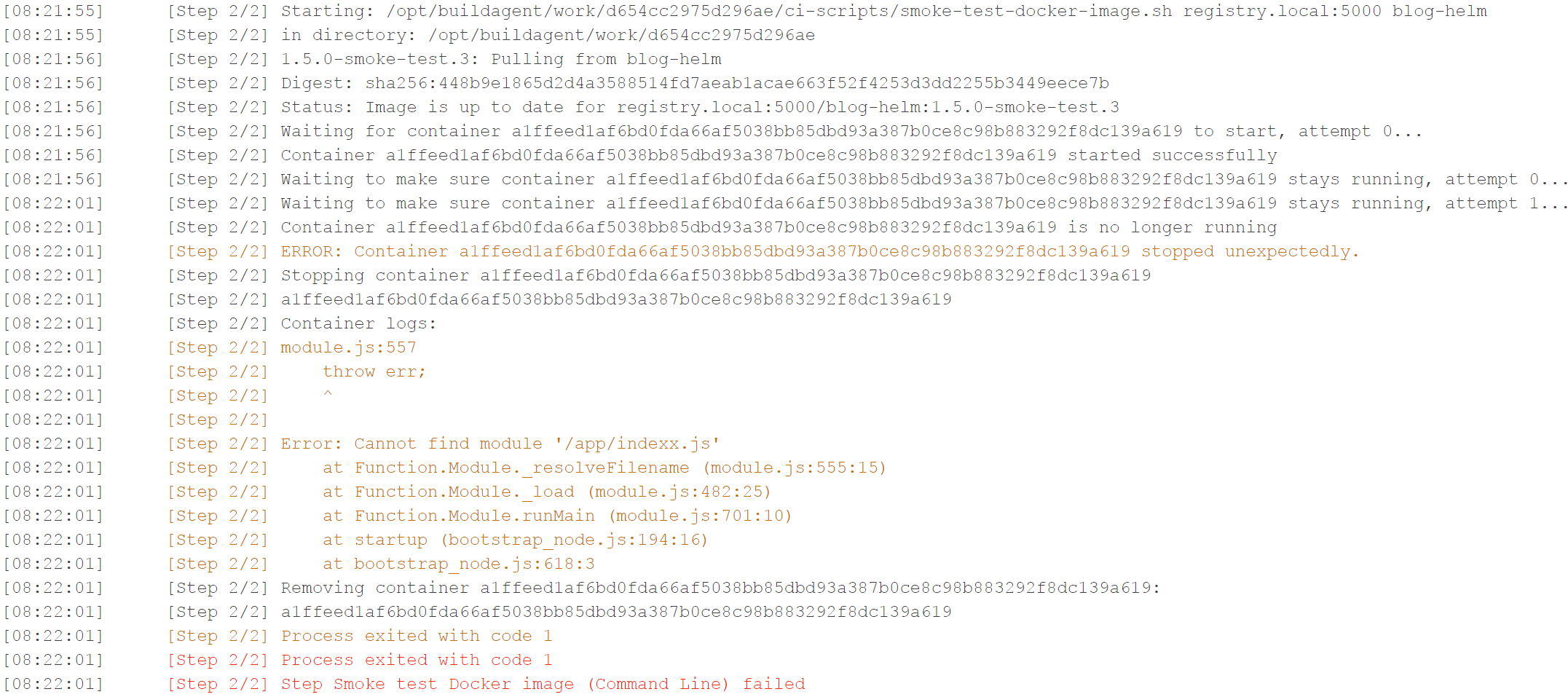
The container starts successfully, but a few seconds later it dies. The smoke test script prints the container logs, so we can clearly see that nodeJS exited because it couldn’t find the file /app/indexx.js.
This smoke test costs a bit more than 30’’ when it is green and less when it is red. Including some overhead for preparing and starting the build, this means that, on the happy flow, we have almost an entire minute to wait before we can deploy our application. What are we buying with this minute to justify spending it?
The checks we’re doing (Can we pull the image? Does the container stay up?) would be implicit in an integration test, because you have to start the container in order to do the integration test against the running application. The advantage with a separate smoke test is that it’s easier to troubleshoot what went wrong. If you see a failed smoke test, you understand that there’s nothing wrong with your integration tests but something more fundamental has gone wrong.