In the previous post, I talked about static code analysis and how it can be useful in enforcing and maintaining a consistent coding style, but also in catching subtle bugs and code smells. The focus was on two tools, jscs and jshint. What other tools and techniques can you use?
Another problem you can encounter is inconsistent file names. Just like code elements, there are many ways to name a file. Developers with different backgrounds have different habits, so before you know it, you can end up with a file structure like this:
- lib
|-- Utilities.js
|-- factory.js
- Controllers
|-- home_controller.js
|-- Products.js
|-- pricesController.js
That’s not pretty to look at and it’s definitely not fun to work with. Luckily, there are tools out there to save the day. Our build system at work is based on grunt, so it was easy to add grunt-filenames in the pipeline. That tool allows you to specify regular expression rules and overrides tailored to your needs. In the example above, you can specify for example:
- all folders must be lowercase
- all files must be PascalCase
- all files inside the Controllers folder must end in Controller.js
and any violation will make the build break. No need to check for these things during code reviews any more.
Back to the content of the files. What can you do beyond jscs and jshint?
A simple approach is to search for a text pattern that you don’t want people to use in the code. As a use case, consider unit tests. We use chai at work as an assertion library. Chai has two flavors: expect and assert. If you decide to use one, it’s best to avoid using the other (again because of readability and maintainability of the code base). You can use a tool like grunt-search and break the build if your unit tests contain the patterns “assert(“ or “assert.”. It’s a bit of a blunt knife, but it can do the trick and it can search in any type of text file.
When it comes to JavaScript though, you can try to build something more sophisticated. One frequent comment I leave during code reviews is that all unit test names must start with the word ‘should’. Let’s see it in code:
// valid
it('should calculate the sum of two numbers', function() {});
// invalid
it('calculates the sum of two numbers', function() {});
// invalid (uppercase Should)
it('Should calculate the sum of two numbers', function() {});
You might’ve guessed why: readability and maintainability. When you get back the full report of the unit tests that failed, you’ll find it easier to read when they’re written in the same style.
For only a fraction of the time I spend in code reviews, I developed two prototypes to automatically detect this issue. They both work with tools that parse the JavaScript code and provide you the syntax tree to play with. You should be hearing the voice in your head: “Power! Unlimited power!”. The first prototype is built with esprima and the second one is a jscs plugin.
We rolled out the jscs plugin solution at work yesterday and it works fine. Why did we go for the jscs plugin approach? Because it’s always best to stand on the shoulders of giants.
jscs will call your custom plugin. Guess who else calls jscs? Your text editors. I tried it out in Atom, Sublime Text, IntelliJ. I have to say, it was very satisfying to see all these editors highlight the code as invalid with my error message. And as far as fail fast feedback goes, there’s nothing faster than seeing it fail as you type.
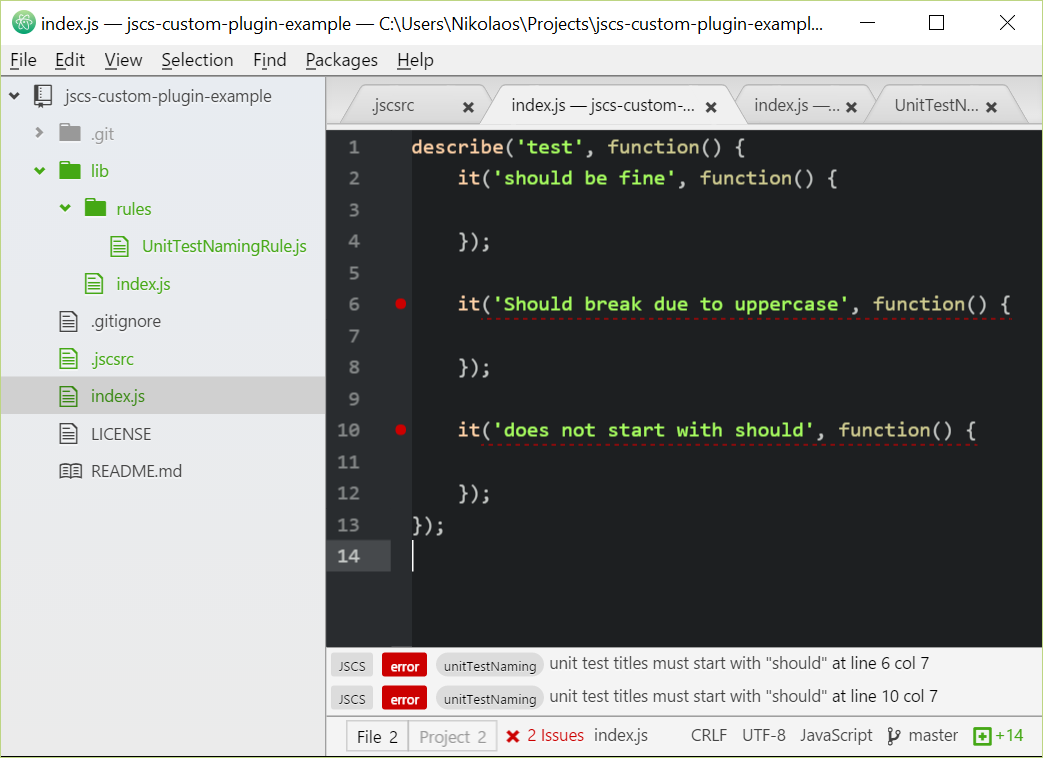
You don’t have to change anything else in your build pipeline either. Your plugin is part of jscs, which makes it part of your build process.
Finally, you always want to be able to tell the machine that you’re still in control (well, for now). In other words, you need to be able to disable the rule if you have to. When you build your custom validation as a jscs plugin, you can override it with inline comments, just like you would do with any jscs rule.
One last tip: consider prefixing your custom rules’ names to avoid any clashes. Depending on how psyched you are with all this, you may want to write a custom rule that validates your custom rules are prefixed!
With this simple custom rule in place, a door has been opened. The obvious change is that we no longer have to worry about this convention in the code reviews. The less obvious change remains to be seen: will this small new feature tempt other team members to build on top of it and further change their mindset, from manual towards automated? Let’s see.
Appendix
prototype based on esprima
LowercaseShouldVisitor.js
var Visitor = require('./Visitor');
/**
* Validates that all mocha "it" functions should have a description
* that starts with a lowercase "should".
* @class
* @extends Visitor
*/
function LowercaseShouldVisitor() {
Visitor.call(this);
}
LowercaseShouldVisitor.prototype = Object.create(Visitor.prototype);
LowercaseShouldVisitor.prototype.visitCallExpression = function(node) {
// it could be a "it('should')" call
if (node.callee.name === 'it') {
if (node.arguments[0].value.indexOf('should') !== 0) {
throw new Error('invalid argument to it: ' + node.arguments[0].value);
}
}
// it wasn't, so call base class
Visitor.prototype.visitCallExpression.call(this, node);
};
module.exports = LowercaseShouldVisitor;
Visitor.js
/**
* Base class for all visitors.
* @class
*/
function Visitor() {}
/**
* Visits the given esprima node.
* @param {Object} node - The esprima node to visit.
*/
Visitor.prototype.visit = function(node) {
var visitor;
if (!node) {
throw new Error('node not given');
}
if (!node.type) {
throw new Error('node has no type');
}
// dispatch to a handler named after the node.type
// e.g. if node.type is 'Program', call this.visitProgram
visitor = this['visit' + node.type];
if (!visitor) {
throw new Error('not supported: ' + node.type);
}
visitor.call(this, node);
};
Visitor.prototype.visitProgram = function(node) {
var i;
for (i = 0; i < node.body.length; i++) {
this.visit(node.body[i]);
}
};
Visitor.prototype.visitVariableDeclaration = function(/*node*/) {
// don't care
};
Visitor.prototype.visitExpressionStatement = function(node) {
this.visit(node.expression);
};
Visitor.prototype.visitCallExpression = function(node) {
var i;
for (i = 0; i < node.arguments.length; i++) {
this.visit(node.arguments[i]);
}
};
Visitor.prototype.visitLiteral = function(/*node*/) {
// don't care
};
Visitor.prototype.visitFunctionExpression = function(node) {
this.visit(node.body);
};
Visitor.prototype.visitBlockStatement = function(node) {
var i;
for (i = 0; i < node.body.length; i++) {
this.visit(node.body[i]);
}
};
Visitor.prototype.visitIdentifier = function(/*node*/) {
// don't care;
};
Visitor.prototype.visitFunctionDeclaration = function(node) {
this.visit(node.body);
};
Visitor.prototype.visitReturnStatement = function(node) {
this.visit(node.argument);
};
Visitor.prototype.visitMemberExpression = function(node) {
this.visit(node.object);
};
Visitor.prototype.visitBinaryExpression = function(node) {
this.visit(node.left);
this.visit(node.right);
};
module.exports = Visitor
analyzer.js
var LowercaseShouldVisitor = require('./LowercaseShouldVisitor');
/**
* Analyzer module.
* @module analyzer
*/
module.exports = {
/**
* Parses and validates the given file.
* @param {String} file - The JavaScript file to parse and validate.
*/
parse: function(file) {
var contents;
var tree;
var visitor;
if (!file) {
throw new Error('file is required');
}
contents = require('fs').readFileSync(file, { encoding: 'utf-8' });
if (!contents) {
throw new Error('file ' + file + ' is empty');
}
tree = require('esprima').parse(contents);
if (!tree) {
throw new Error('esprima could not parse ' + file);
}
visitor = new LowercaseShouldVisitor();
visitor.visit(tree);
return true;
}
};
prototype based on jscs
index.js
module.exports = function(conf) {
conf.registerRule(require('./rules/test_naming_rule'));
};
rules/test_naming_rule.js
/**
* This is a custom jscs rule that verifies the naming of tests.
* Tests are written in mocha using the 'it' method.
* This rule, called 'testNaming', verifies that the test names
* start with the prefix you choose.
* For example, if you want all of your tests to start with the word 'should',
* add this rule to your jscsrc:
* "testNaming": "should "
*/
function TestNamingRule() {
}
TestNamingRule.prototype.getOptionName = function() {
return 'testNaming';
};
TestNamingRule.prototype.configure = function(options) {
this._prefix = options;
};
TestNamingRule.prototype.check = function(file, errors) {
var prefix = this._prefix;
if (!prefix) {
// we don't have a prefix, no need to validate anything
return;
}
file.iterate(function(node/*, parentNode, parentCollection*/) {
var firstArg = null;
if (!node) {
// no node?
return;
}
if (node.type !== 'CallExpression') {
// only looking for call expressions
return;
}
if (node.callee.name !== 'it') {
// only looking for 'it' calls
return;
}
if (!node.arguments || !node.arguments.length) {
// no arguments?
return;
}
firstArg = node.arguments[0];
if (!firstArg) {
// first argument is the test name, somehow it's missing?
return;
}
if (firstArg.type !== 'Literal') {
// don't dive into this if it's not a plain string literal
return;
}
// does it start with the prefix?
if (firstArg.value.indexOf(prefix) !== 0) {
errors.add(
'Test names must start with "' + prefix + '"',
firstArg.loc.start);
}
});
};
module.exports = TestNamingRule;